Apply filter pushdown to source rows for the right outer join of matched only case #438
Conversation
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
|
Gentle ping @tdas @zsxwing @jose-torres @brkyvz |
|
Any comments? Gentle ping @tdas @brkyvz @zsxwing @gatorsmile |
|
Any reason why this was not merged or at least reviewed? |
jaceklaskowski
approved these changes
Aug 5, 2021
| @@ -214,7 +214,7 @@ case class MergeIntoCommand( | |||
| private def isMatchedOnly: Boolean = notMatchedClauses.isEmpty && matchedClauses.nonEmpty | |||
|
|
|||
| override lazy val metrics = Map[String, SQLMetric]( | |||
| "numSourceRows" -> createMetric(sc, "number of source rows"), | |||
| "numSourceRows" -> createMetric(sc, "number of source rows participated in merge"), | |||
There was a problem hiding this comment.
nit: s/participated in merge/involved
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
The reason for this optimization is similar to #432.
In matched only case, we use a right outer join between source and target to write the changes.
Due to the non-deterministic UDF
makeMetricUpdateUDF, the predicate pushdown for source rows is not applied. This PR is manually adding a filter beforeProjectionwith the non-deterministic UDF to trigger filter pushdown.Besides the performance improvement by filter pushdown, without this, Spark Driver may easily trigger frequent full GC problem if the source table contains mass files:

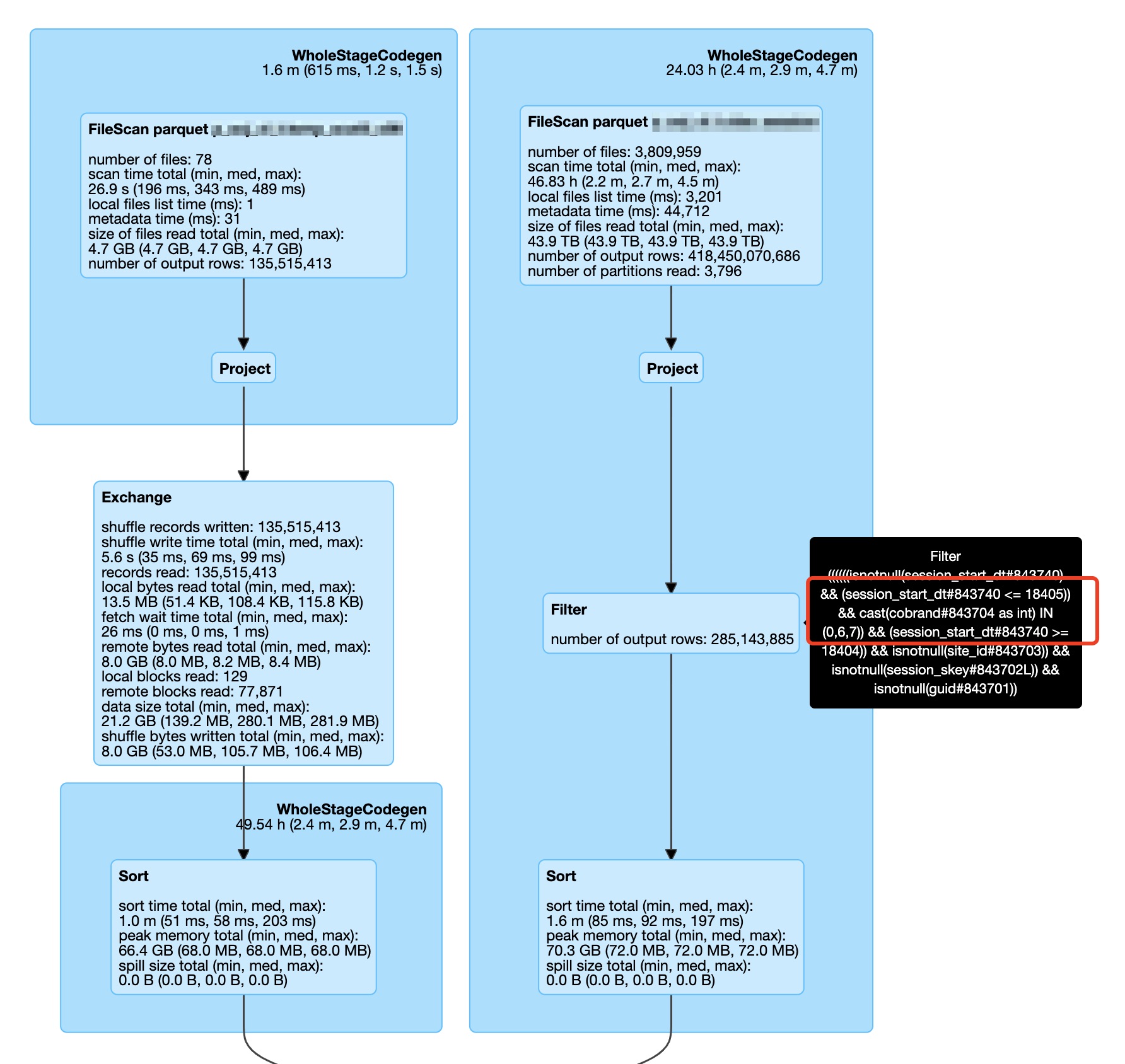
(in our inner version, we use target left outer join source instead of source right out join target, so the right side in the below graphs is source table)
From the Class Histogram when Spark Driver full GC, we can see 3.8 million
SerializableFileStatuswhich basically matches the file count in the source table in above graphs. This hold memory could not be GC during the join processing.After applied this optimization, the frequent full GC problem caused by this scenario had gone. And the performance of this out join was greatly improved.