Apply filter pushdown to the inner join to avoid to scan all rows in parquet files #432
Conversation
|
Can you add a unit test to verify whether this is working? |
The difficult part for unit test is I cannot extract the inner plan information. So I just test it and check it from Spark UI We can see the filter is added after the two projects ( After patching: We can see the filter is added before the two projects ( |
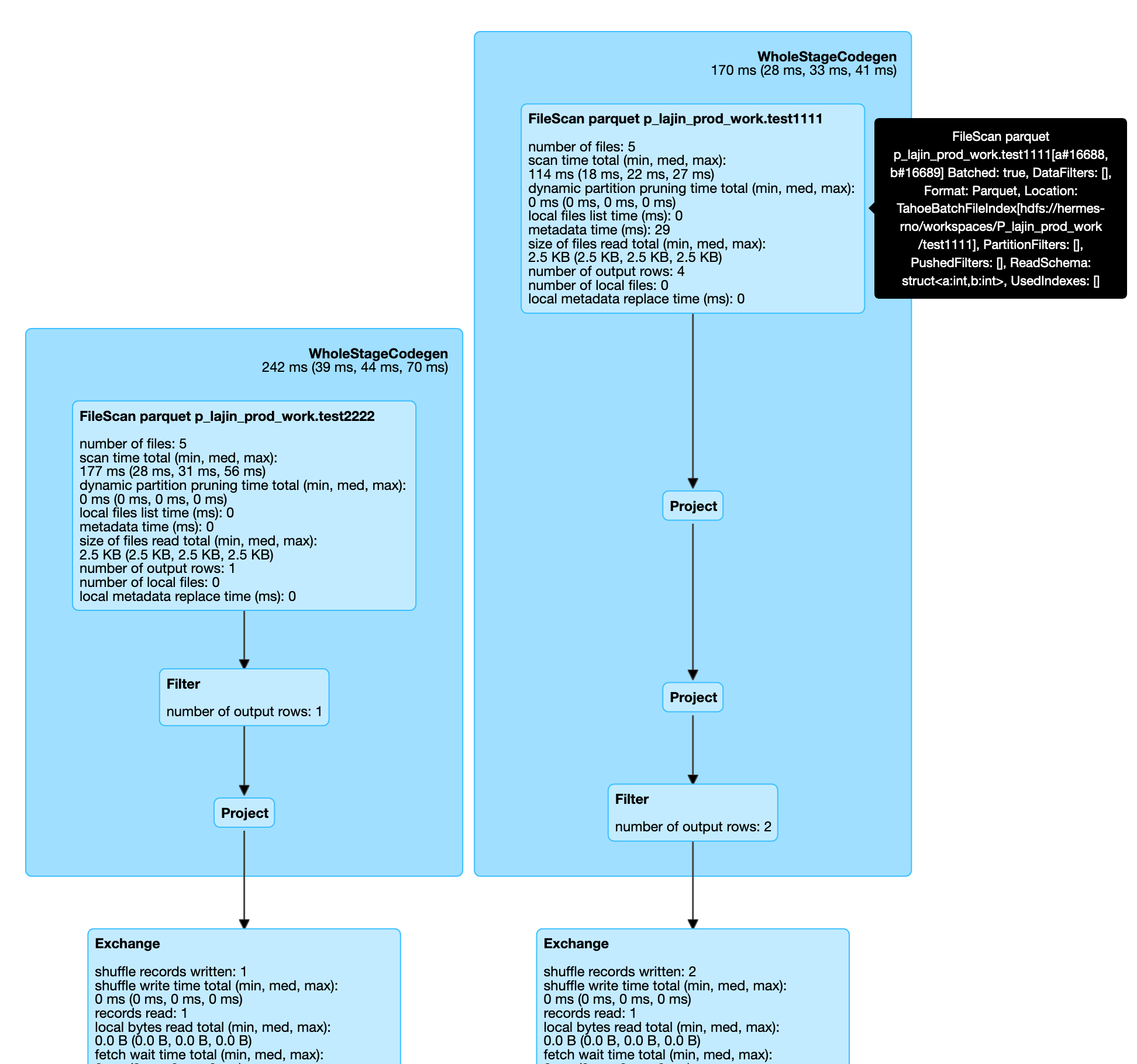
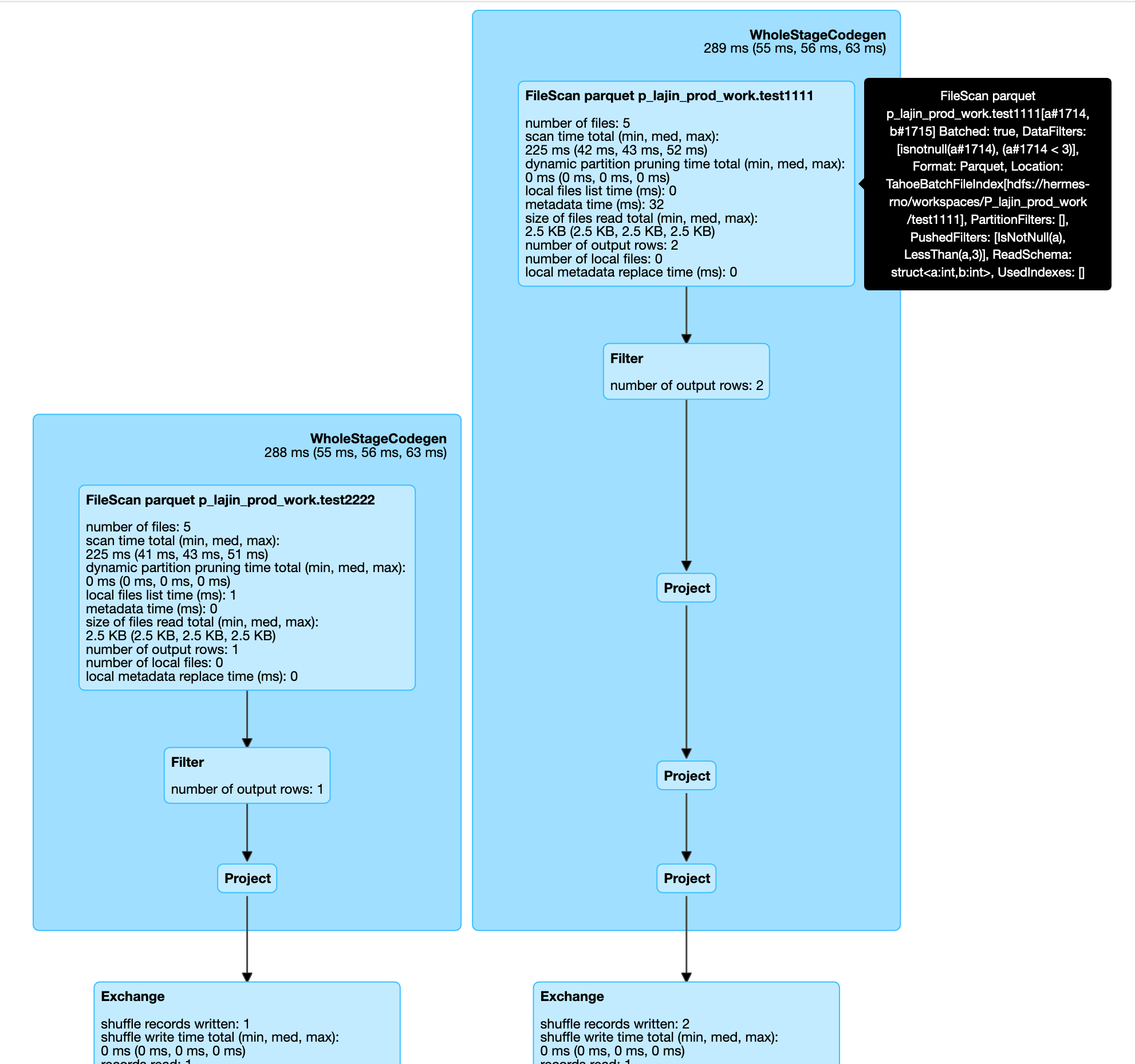
|
This is a very good find. Thank you for finding it. I see that this is hard to unit test. ... hmm let me think about how to unit test this. |
|
Gentle ping @tdas @zsxwing @jose-torres @brkyvz |
|
Hi @LantaoJin, thank you for submitting this PR! By adding SQLQueryListener, you should be able to capture the internal execution of the plan. Then we can compare the metrics on the number of rows read to unit test this. |
|
Any more comments? Gentle ping @tdas @brkyvz @zsxwing @gatorsmile |
In
MergeIntoCommand, it uses a inner join to find touched files. But the targetDF contains some non-deterministic columns (e.gFILE_NAME_COL). That will prevent the target table from applying parquet filter pushdown. So current implementation scans all rows in parquet files of targetDF (has skipped the files which not contains any matched rows). But in the worst case, it still could scan all data in the whole target table. So we need to add a filter before addingwithColumnto enable the Parquet filter pushdown. Without this patch, the PushedFilters in FileScanExec is empty. With this patch, all target only predicates could be pushdown to parquet FileScanExec.