设计一个算法,输入一个长字符串(value,长度不限),输出一个不重复的短字符串(key,长度限制为8),同时需要存储长字符串和短字符串的对应关系,能根据短字符串快速查询其唯一对应的长字符串。
从需求分析中看出,系统并不关心反向解密的复杂度,所以从性能方面考虑,首选非加密哈希算法,再考虑到哈希碰撞概率,推荐使用MurmurHash算法。MurmurHash 提供了两种长度的哈希值,32bit和128bit,因为需求中规定短链最大长度不能超过8,也就是8位62进制(48位左右,128位将超出),所以选择32位哈希值(最大容量在34亿左右)。
采用哈希算法则必须考虑哈希碰撞问题,当哈希值重复时,可通过数据库查询其对应的长链是否相同,如果长链不同则发生哈希碰撞,这时可以通过再哈希法重新生成短链。如果数据量较大,为提高性能可通过布隆过滤器排重。
整体流程图如下:

缺点:累计大数据量情况下,哈希碰撞率增加,解决哈希碰撞会降低系统效率。
可以设计一个ID自增生成器(发号器),当收到一个长链转短链的请求时,发号器为其分配一个 ID,再将其转化为62进制,拼接到短链域名后面就得到了最终的短网址。发号器即成为设计的关键,分布式环境下一般分为有中心方案和无中心方案。
典型的为UUID和Snowflake算法,前者为128位,后者为64位,均超过8位62进制的容量范围,都不能满足系统需求。
- Redis方案,incr指令原子性加上单线程机制,能有效的保证分布式环境下的性能和安全。在极端性能需求时,可以考虑分片(每片的初始值和步长不同即可)。
- Mysql方案,利用mysql的自增主键也能实现发号器,但是自增主键在集群环境(分片)下,无法保持有效支撑。
- ZK方案,原生的分布式支持,性能上较redis差一些。
整体流程图如下: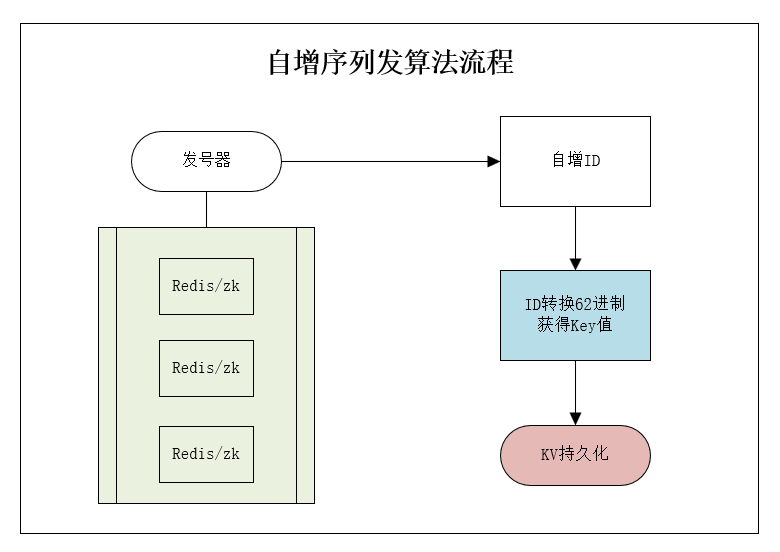
缺点:需要中间件支持,考虑到高可用和高负载的情况时,架构上会相对复杂。
理论上8位62进制可支持281万亿个链接,但实际生产过程应该不允许无限制扩容,会设计淘汰算法限制系统容量,提高查询效率。典型的淘汰算法包括FIFO,LFU,LRU,但是从产品角度看,这三个算法都不是很合适的算法,因为用户的需求,一般都是需要明确知道短链的有效期,而不是由系统来确定短链的有效期。所以更应该采用过期淘汰法。
- 优点:key的长度受限导致key数量受限,这种关系可以最大程度上保证系统的容量
- 缺点:需要维护一对一关系,相同的value必须返回相同的key,在空间或者时间上必然有一方要做出牺牲,且系统处理复杂度增高
- 优点:系统复杂度降低,效率高
- 缺点:相同的value返回不同的key,会降低系统容量
对比哈希法和发号器法,显然发号器法的性能和容量要较哈希法更好,所以采用发号器法实现key值生成。为提高性能,kv存储方案采用多对一方案。
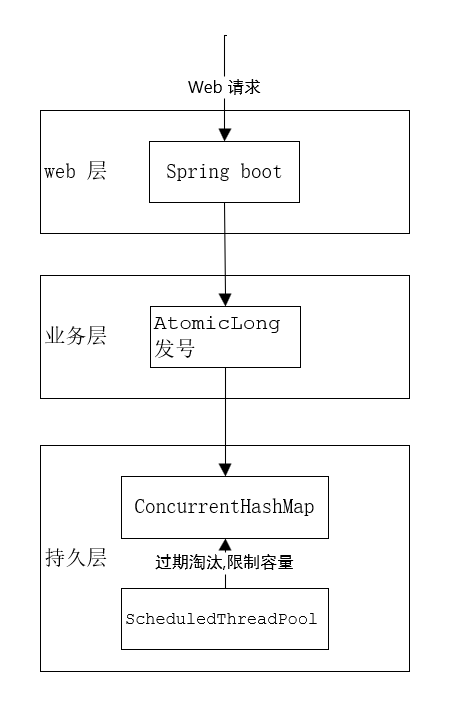
内存中发号器可以使用原子类(AtomicLong)来实现,保证并发下的发号唯一性。
过期淘汰缓存,采用ConcurrentHashMap(存储容器) + ScheduledThreadPool(定时删除)来实现,虽然ScheduledThreadPool的DelayedWorkQueue也是个无界队列,容易造成内存溢出,但是对存储容器(ConcurrentHashMap)做了最大容量限制,可以限制内存溢出情况。
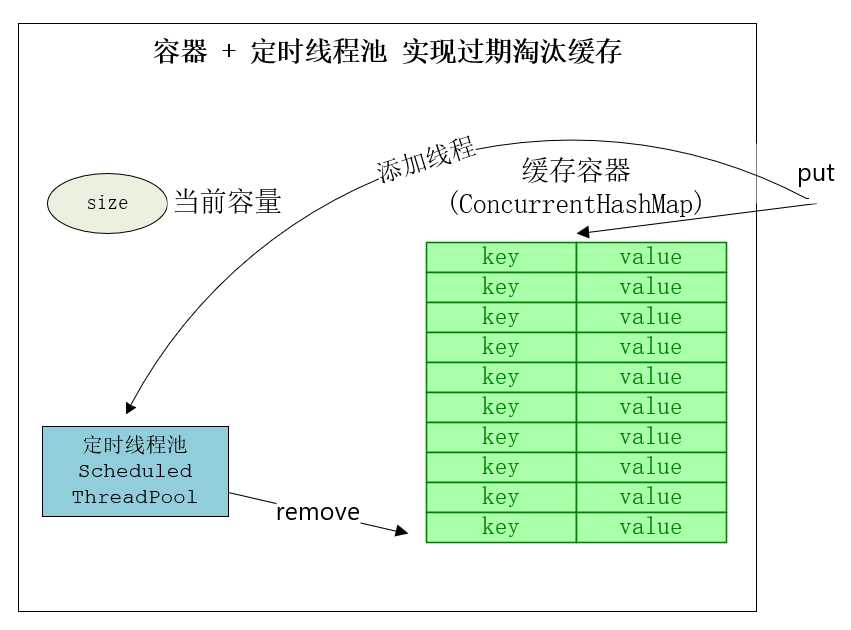
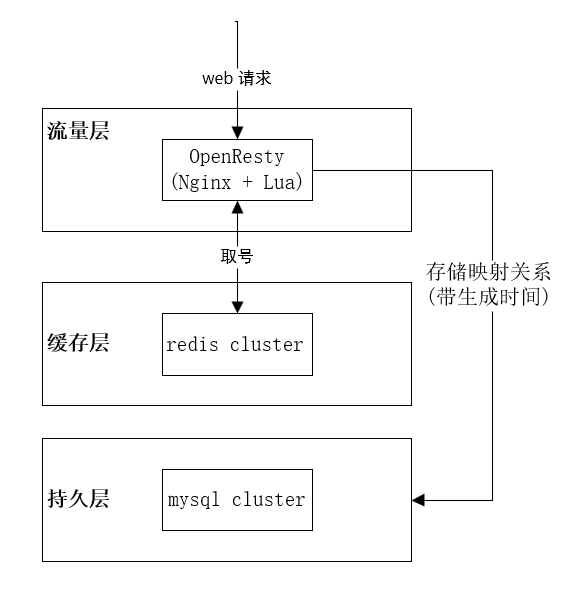
详细设计如上,架构图如下:
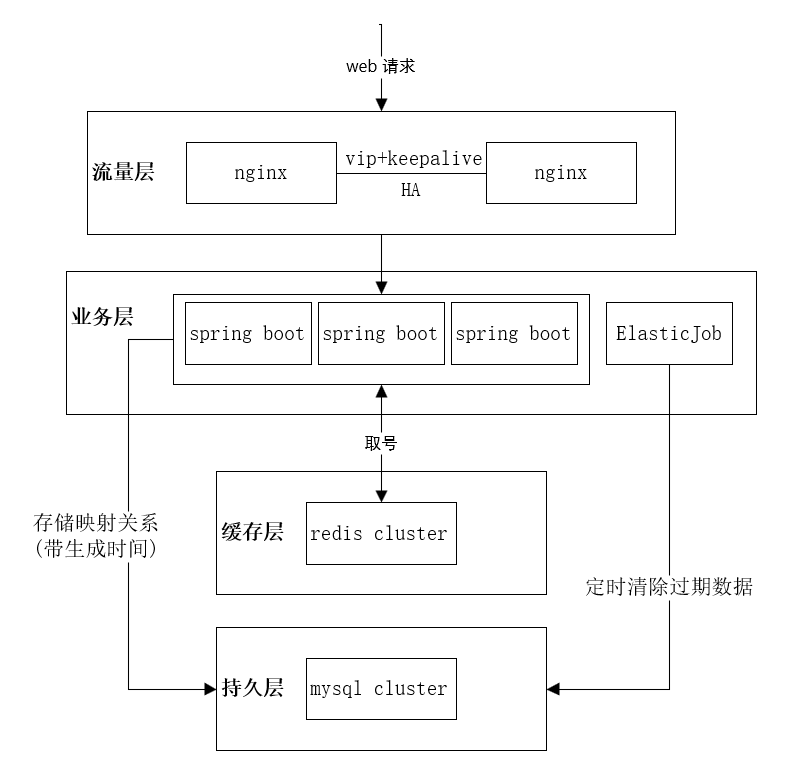
nginx高可用作负载均衡,web服务通过redis集群取号,并将映射关系(带时间戳)存储到mysql。对于过期数据可采用定时任务淘汰,定时任务可通过ElasticJob实现保证分布式和高可用。
直接引入了OpenResty(基于Nginx与Lua的高性能Web平台),由于Nginx的非阻塞IO模型,支持高并发连接,同时OpenResty可直接访问redis缓存,也可以直接连mysql,不需要再通过业务层连这些中间件,性能可进一步提升。
)
jmeter新建两个线程组(模拟转换短链接和获取长链接),分别以100线程循环20次测试TPS。
所有截图均在img目录