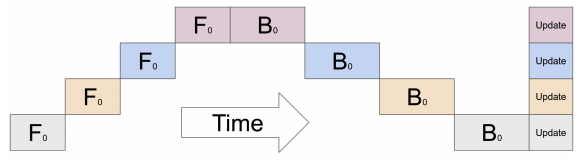
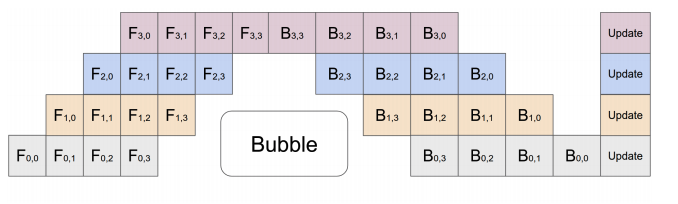
基于pytorch提供的PIPELINE PARALLELISM
功能,参考了transformer包提供的llama的代码后,给llama架构实现了一套流水线并行训练代码。

- 之前看到
刘聪nlp对chatglm实现了流水线并行文章,非常羡慕,也想自己写一个。 - 最近有时间,为了提高自己对
llama模型结构的认识、提高对transformers代码的了解。 - 虽然
模型并行非常好用,但是不能总是用这个吧,太慢了,那就自己实现一个pipeline来提高代码能力。 - 当前,训练框架有很多,比如
deepspeed、transformers、TencentPretrain等。也想自己实现一个框架,支持流水线并行、张量并行等。本项目,就当先起个步。目标是自己实现一套支持3d并行的大模型训练库(哈哈哈,单纯口嗨)
- 之前,
刘聪nlp他是用deepspeed来实现的,但是我对deepspeed不熟悉。因此我在调研了pippy、pytorch之后,决定,还是用pytorch来实现。 - 其实非常简单,就是把llama的模型代码,从之前的
nn.ModuleList封装,改为nn.Sequential封装。
- 可以直接将
transformers的llama模型转换成拥有流水线并行的llama模型。 - 基础训练流程已经发布(但是比较粗糙)。
虽然当前基础的训练流程已经发布,但是比较粗糙,具体体现在:
- 数据集:我只是提供了随机数生成,但是没做
huggingface的datasets教程,对小白来说,门槛依然有点高。 - 多gpu负载不合理:当前的网络层分配,负载是不合理的。体现在,最后一张卡的显存占用非常大,还需要优化。
- 支持
fb16、bf16等精度工作,还没有做。